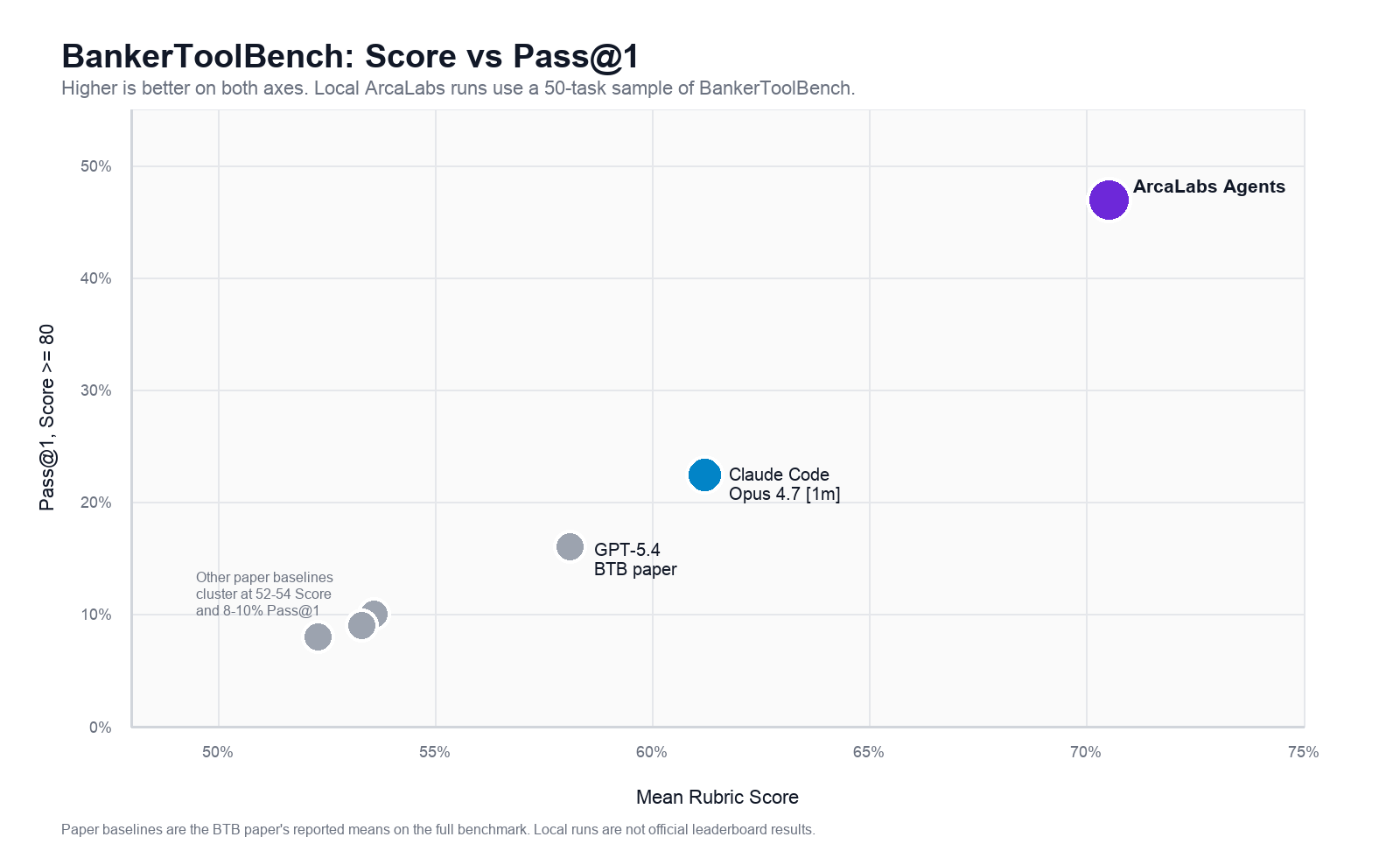
BankerToolBench (BTB) measures the thing that actually matters in banking: a complete deliverable that survives detailed review. We ran ArcaLabs Agents on a 50-task sample of the public BTB data and beat every published frontier-agent baseline — most importantly on Pass@1, the strict bar for work a banker would actually ship.
Overall performance
We ran ArcaLabs Agents on a 50-task sample randomly drawn from the publicly available BankerToolBench data, against a vanilla Claude Code baseline on the same sample, and the BTB paper's published baselines on the full 100-task benchmark.
ArcaLabs Agents reach 70.5 mean Score and 46.9% Pass@1 in their best run — a 9.3-point Score gain and a 2.1× Pass@1 lift over the raw vanilla baseline on the same sample, and 12.4 Score points above the paper's strongest published agent.
| Agent | Mean | Median | Pass@1 |
|---|---|---|---|
| ArcaLabs Agents | 70.5 | 76.2 | 46.9% |
| Claude Code, Opus 4.7 [1m] | 61.2 | 65.4 | 22.4% |
| GPT-5.4 | 58.1 | n/a | 16.0% |
| Gemini 3.1 Pro | 53.6 | n/a | 10.0% |
| Claude Opus 4.6 | 53.3 | n/a | 9.0% |
| Claude Opus 4.5 | 52.3 | n/a | 8.0% |
Table 1. ArcaLabs and Claude Code are run on a 50-task sample of BankerToolBench. Paper baselines are three-run means on the full 100-task benchmark, from the BankerToolBench paper. Paper medians are not published.
Evaluation methodology
BankerToolBench contains 100 end-to-end investment banking tasks built with input from 502 investment bankers. Tasks require agents to navigate data rooms, use market and filings tools, and produce Excel, PowerPoint, PDF, Word, or CSV deliverables — finished work products that have to survive the kind of detailed review an associate or VP would actually apply.
Each deliverable is graded by Gandalf, the paper's banker-aligned LLM-as-judge harness, against a weighted rubric of banker-authored criteria. A task Score is the weighted percentage of those criteria the deliverable passes:
Pass@1 is stricter: the deliverable counts as passing only if its Score is at least 80. A spreadsheet that is mostly right, a deck with inconsistent figures, a model that cannot be audited — all land below the line.
Our runs use a 50-task sample randomly drawn from the publicly available BTB data, with Gemini 3.1 Flash Lite Preview as the inner judge; the paper baselines use the full 100 tasks across three runs. Full session logs, evaluation results, and per-task classifications are tracked in our eval repo.
The agent environment recovers Pass@1
Wrapping the same Opus 4.7 [1m] model in the ArcaLabs agent environment moves the headline metric from 22.4% to 46.9% Pass@1 on the same 50-task sample — a 2.1× lift on the stricter threshold, off the same base model and the same data room access.
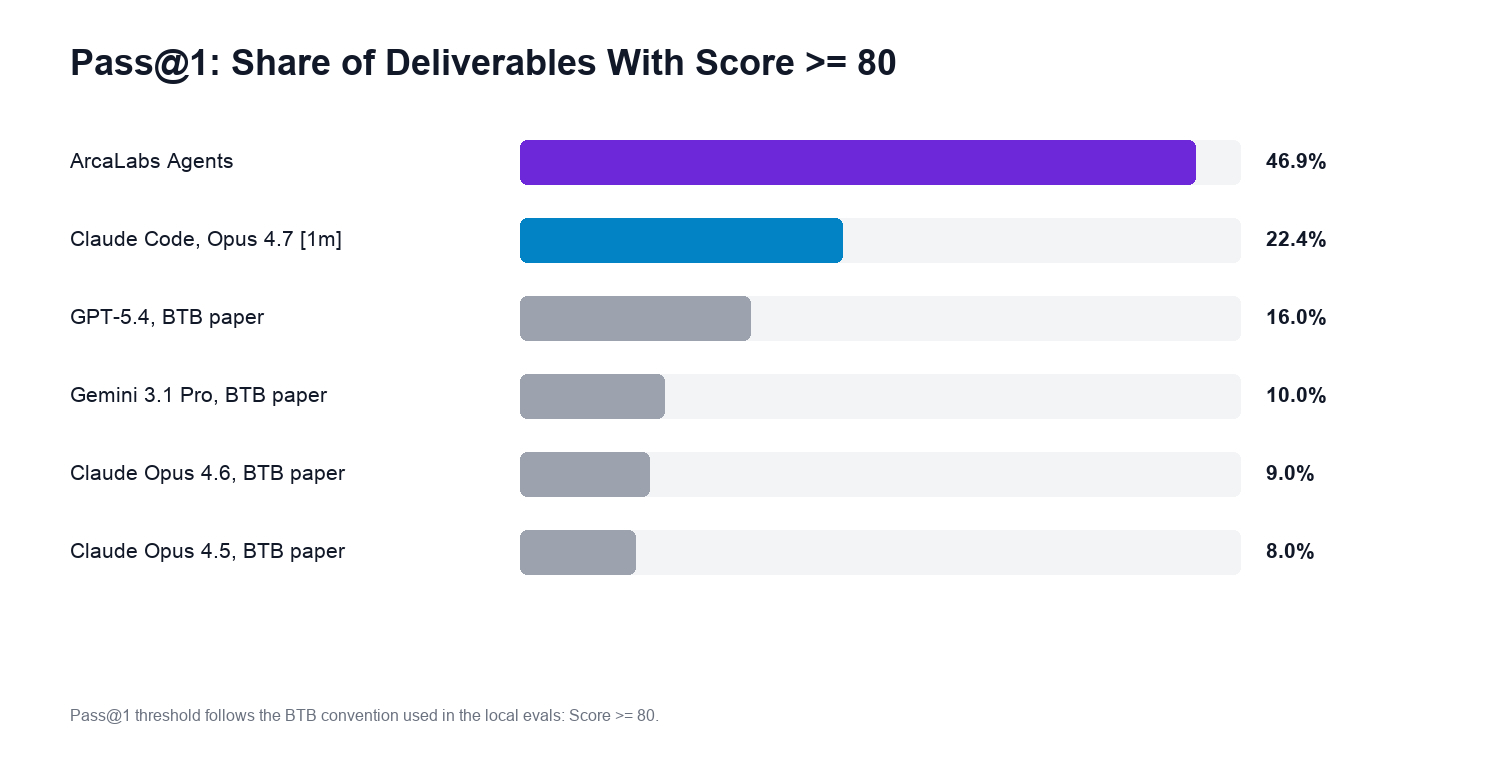
Mean Score moves from 61.2 to 70.5. The Score gain is meaningful, but the Pass@1 gain is the load-bearing number: a Score-of-65 deliverable does not actually meet the bar for a banker review. Pass@1 measures the share of deliverables that finish well enough to use.
Where the lift lives, and where it doesn't
The aggregate Pass@1 gain is not uniform. Product mix matters.
| Product | n | ArcaLabs Agents | Vanilla Claude Code | ||
|---|---|---|---|---|---|
| Mean | Pass@1 | Mean | Pass@1 | ||
| M&A | 29.3 / 30 | 70.5 | 38.0% | 63.5 | 20.0% |
| Levfin | 10.0 / 10 | 66.1 | 53.3% | 58.7 | 10.0% |
| ECM | 4.3 / 5 | 75.9 | 62.2% | 78.9 | 80.0% |
| DCM | 2.7 / 3 | 42.4 | 0.0% | 26.0 | 0.0% |
| M&A, Levfin | 1.0 / 1 | 28.9 | 0.0% | 33.3 | 0.0% |
Table 2. Performance by product. Levfin and M&A improve meaningfully over the raw run on Pass@1. DCM remains unsolved in this sample. ECM looks strong in both runs, but the sample has only five tasks, so the result is directional.
Financial modeling shows the clearest lift over raw Claude Code. Client and marketing materials remain harder than they look, because the grader checks internal consistency, presentation quality, and stakeholder utility across the full work product — not just whether a slide exists.
| Workflow category | n | ArcaLabs Agents | Vanilla Claude Code | ||
|---|---|---|---|---|---|
| Mean | Pass@1 | Mean | Pass@1 | ||
| Financial Modeling & Scenario Analysis | 18.7 / 20 | 70.3 | 49.7% | 59.1 | 20.0% |
| Valuation & Pricing Analysis | 16.0 / 16 | 67.0 | 30.3% | 61.0 | 25.0% |
| Client & Marketing Materials | 10.0 / 10 | 63.5 | 43.3% | 63.2 | 20.0% |
| Other / sparse categories | 3.0 / 3 | 68.0 | 27.8% | 69.4 | 33.3% |
Table 3. Performance by workflow category. Sparse workflow categories combine Process & Timeline Management, Aftermarket Performance Trading, and Market Analysis & Investor Engagement for readability.
Limitations and future work
- Judge model. Evals use Gandalf with Gemini 3.1 Flash Lite Preview as the inner judge, while the paper validates Gandalf with different judge settings.
- Comparability. Paper baselines use the BTB paper's setup; ArcaLabs runs use the ArcaLabs agent environment. The raw vanilla comparison on the same sample is the cleaner A/B.
- Small categories. DCM, ECM, and the mixed M&A/Levfin subset have low task counts in the sample, so category-level results are directional.
Conclusion
BankerToolBench is valuable because it measures the thing that matters in banking work: a complete deliverable that can survive detailed review. The best published baseline in the paper, GPT-5.4, reaches 58.1 Score and 16.0% Pass@1 on the full 100 tasks. Our ArcaLabs sample reaches 70.5 Score and 46.9% Pass@1.
That is not a final leaderboard claim. It is an engineering result. The gap between raw Claude Code and ArcaLabs Agents on the same sample — about 9 Score points and a 2.1× Pass@1 — suggests that real workflow performance is a property of the whole agent system, not just the base model.
In M&A diligence, a comp set with one mismatched multiple does not cost an LLM a token; it costs a credibility hit in the next IC meeting. The work BTB grades is the work bankers ship. We are building toward agents that finish that work the first time, repeatedly, on every product. The next step is the full 100-task benchmark with repeated runs and tighter variance estimates.
Sources. BankerToolBench paper, arxiv.org/abs/2604.11304; ArcaLabs BTB eval summaries from May 18–19, 2026.
Want banker-grade agents on your desk?
See ArcaLabs run your workflows on FactSet data, in your firm's house style.